

 I’m Paul Dixon, CTO here at LibLynx. We understand that access management is a critical piece of your infrastructure, and so we’ve spent a significant amount of the last 6 months developing technology to ensure that we can deliver a highly available and scalable architecture. In short, we want our platform to be at least as good as yours!
I’m Paul Dixon, CTO here at LibLynx. We understand that access management is a critical piece of your infrastructure, and so we’ve spent a significant amount of the last 6 months developing technology to ensure that we can deliver a highly available and scalable architecture. In short, we want our platform to be at least as good as yours!
This is the first in a series of posts where I’ll describe talk about some of the technology we use behind-the-scenes to achieve this. I’m writing with a non-technical audience in mind so I’ll avoid too much jargon, and feel free to contact me directly if you’re interested in discussing in more detail. So let’s dive in!
Why high availability is important to us
LibLynx provides a “Software as a Service” (SaaS) Identity & Access Management solution to publishers through an API. It is used to control access to electronic resources; this means if we’re down, then those resources are down too.
There are lots of things you can’t control that can bring a service down, like server failures, and data center outages. I’ll talk about how we mitigate those in a later post.
Software updates, on the other hand, are well within our control. We aim to release new features, bug fixes and security updates as soon as possible. Although there are lots of ways software deployment can necessitate short downtimes, availability is one of our key metrics. So for us, we needed a way to update our software with zero downtime.
Why is zero-downtime deployment hard?
Deployment is hard when it hasn’t been adequately planned right from the inception of the system design. Frequently, deployment has evolved as a software stack matures from an early alpha to final production.
A typical example of such evolution would be uploading a new build of software to production servers. It’s likely the software services on those servers need restarting to pick up the changes. That restart might take an appreciable time. During the restart, active connections are dropped. After the restart, everything slows to a crawl because caches had to be cleared. Then repeat the process if anything goes wrong.
When you’re in this position, and required to shoot for zero downtime, you discover expensive-to-change decisions in the technology stack make that an uphill battle.
Having experienced that battle in the past, I knew we had to bake in zero-downtime deployments right from the start. One model for this is commonly called blue-green deployment.
Blue-green deployment- a jargon-free analogy

Imagine a grocery store with two checkouts. One blue, one green. When you go to pay for your groceries, only the blue checkout is open, and you join a line of people. It’s the end of blue’s shift, and he’s looking tired. It’s time he was replaced!
You notice the green checkout operator arriving and begin preparing to serve customers, but she doesn’t remove her ‘closed’ sign.
When she’s ready, she flips her sign to open, and the blue checkout guy announces he’s closing his checkout. The customers naturally flock to the green checkout, but the blue checkout is still processing his last customer. Once they’ve completed their purchase, the blue guy can end his shift.
The store has ensured that customers are being served at all times.
Even better, imagine the green checkout operator finds her conveyor belt isn’t working properly. She can still serve customers, but not very fast. Her supervisor reopens the blue checkout, which has been sitting dormant ready to go. Once she’s finished with her customer, green closes her checkout so the belt can be repaired.
That’s blue-green deployment in a nutshell. You prepare a new version of your software stack, and seamlessly direct traffic to it when you’re ready. Ideally, you do this in a way that no requests or transactions are aborted during the change. Plus, you have the added safety net of the last-known-good release ready to flip back if you have unexpected problems.
Turning it into reality
The term Blue-Green Deployment was popularized by Martin Fowler in 2010. The key is to consider the blue and green configurations as entirely separate server systems, rather than services running on the same hardware. Since 2010, virtualized or cloud-based server deployments are increasingly common, making this technique viable for a wide range of applications.
So, we needed to ensure our entire build pipeline can prepare one of these blue or green server stacks whenever the software changes, and ensure our automated tests are run so that we’re ready to release with confidence.
The next consideration is how to perform that crucial flip from blue to green.
Part of our high availability strategy is to be cloud-agnostic. This means we can’t tie our design too closely to any virtualization platform like VMWare or Xen, or to any particular cloud provider like Amazon or Rackspace. We want to be able to deploy anywhere as a hedge against failures from any one provider.
This decision informed the next one; that we’d need a cloud-agnostic way of performing scaling and load balancing, since this varies between providers. That was the final piece of the puzzle – as we researched the most effective ways of doing that, we were also testing for how well each technology could support a true zero-downtime flip between blue and green deployments.
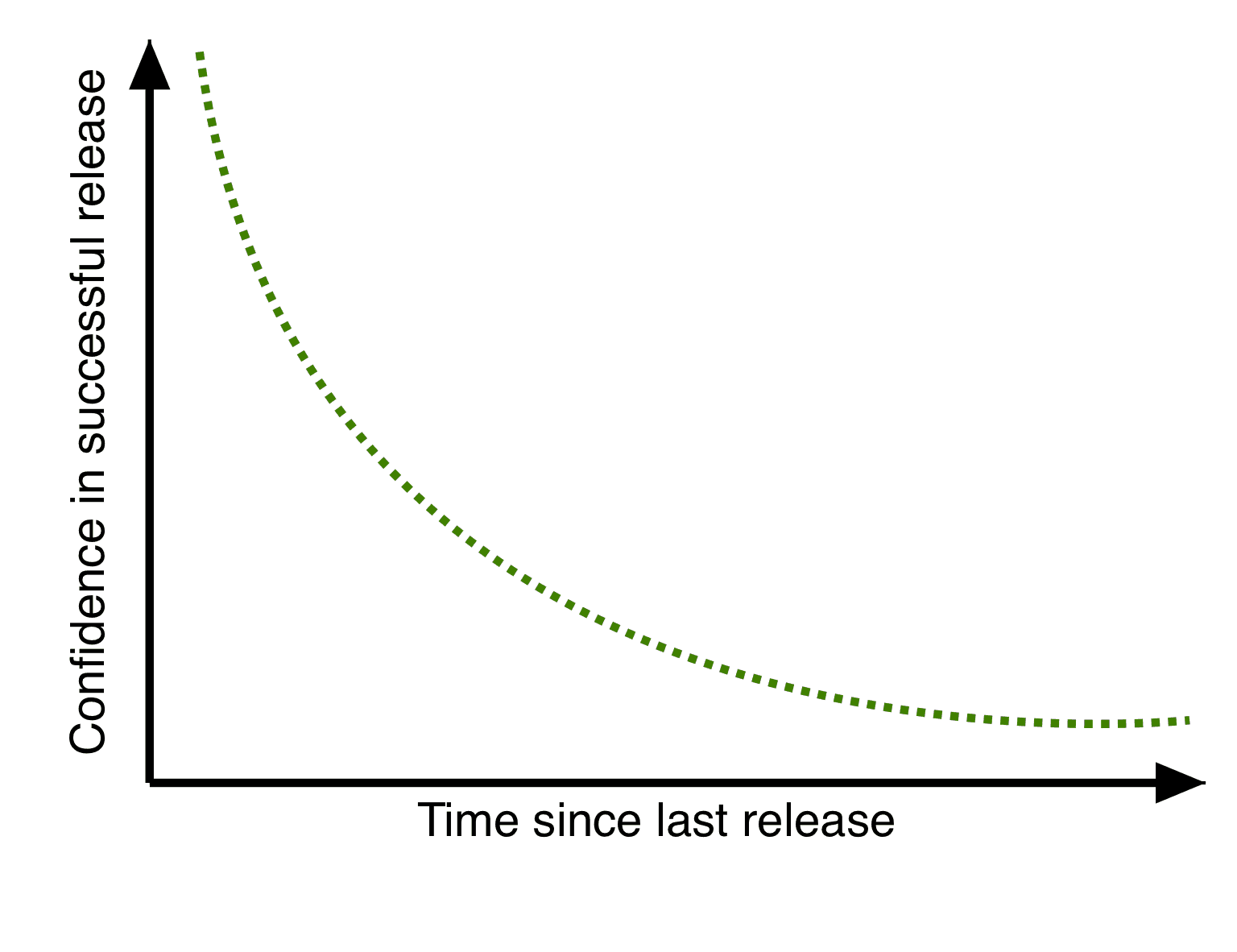
The result? Confident, daily releases
The longer you go between releases, the less confidence you have that it will be trouble-free, no matter how good your test procedures. If you’re releasing every few months, each release is a big event.
Conversely, releasing daily results in much higher confidence. The changes tend to be smaller and easier to audit. The process itself, because it’s a daily thing, becomes smoothly honed.
The end result is that releasing isn’t a big event for us, it’s part of the regular rhythm of our working day.
Credits
Photo adapted from Northland Foods ’70s Interior by Andrew Filer (used and adapted under cc-by-2.0 licence)