
One of the industry issues that’s largely been missing from industry conferences is the destructive impact of robotic access on the publishing economy. Many of us in the industry feel the impact on a weekly – if not daily – basis, and there have been some great posts on the topic (such as here and here), but we need a more open dialogue on the implications and potential solutions.
The good news is that there is a dedicated session on this topic at this year’s Charleston conference, titled Bot war: Will evil AI-scraping bots succeed in destroying our open digital libraries?
We were delighted that our session was voted as one of the 3 ‘Neapolitan sessions’ at Charleston – ‘mini plenaries’ of broader interest that are given a bigger stage.
Read on to learn more about what motivated us to propose the session, who’s involved, and what we’re planning to cover.
Why do we need to talk about Bots?
The automated scraping of content from publisher websites, library catalogs, and other content repositories is not new – but, thanks to the avalanche in AI apps, is reaching epic proportions, with automated traffic exceeding human traffic for the first time in over a decade. The significant expansion of open-access publishing models over the last decade has increased the supply of publicly available content, while the more recent emergence of large language models has fueled AI-driven demand for training content. The result is a locust-like horde of bots mindlessly accessing everything they encounter, and at a scale we’ve never seen before.
There are visible, short term impacts
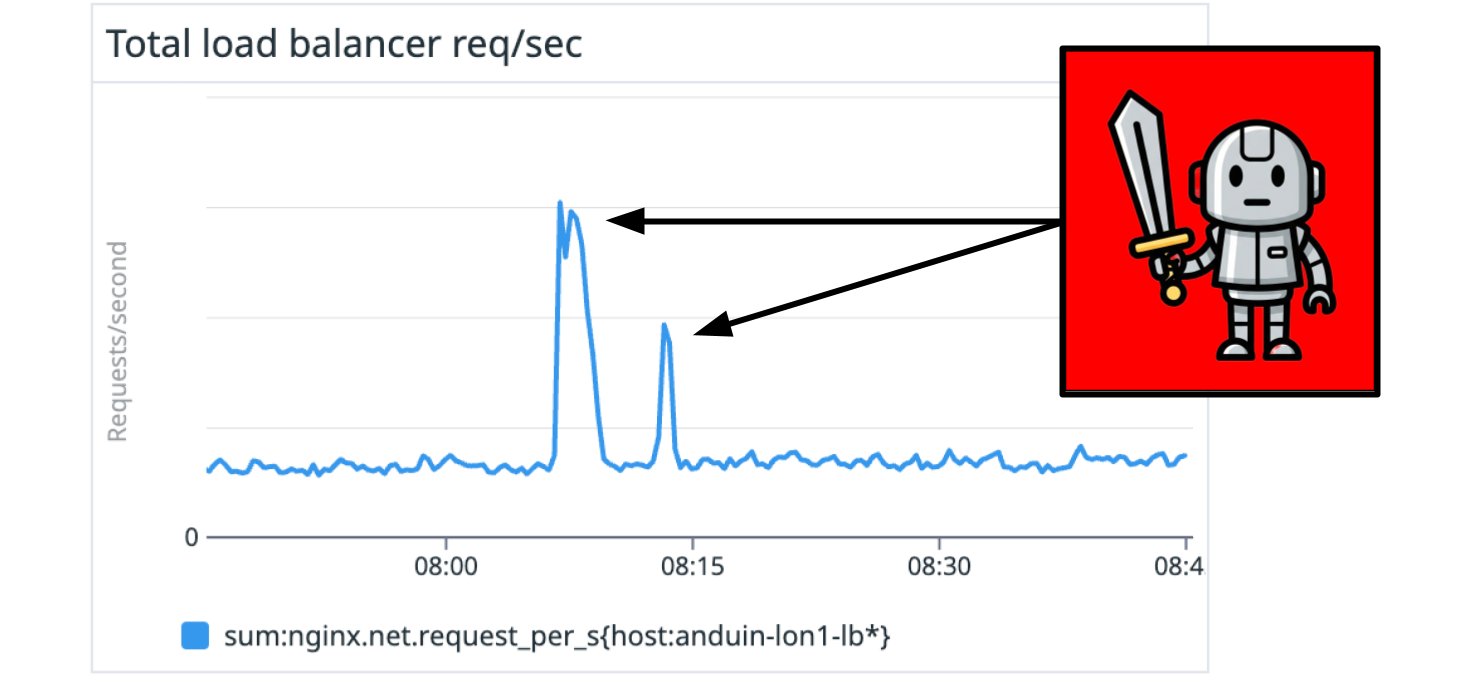
The impact on the scholarly community is significant. The most visible and immediate consequence is that sites struggle to respond, or even go down, as their servers are overwhelmed by high-volume, scripted requests. LibLynx, for example, processes hundreds of millions of access requests each month, bearing witness to the immediate effects of this spike in site scraping, as service delivery platforms swamp us with bot-generated traffic. Some of the spikes are significant – 100x or more the average traffic level. Not many organisations can afford to have that amount of capacity sitting around just in case, so it’s a real engineering challenge. Over the last year, we’ve invested heavily in a radical new architecture to enable us to scale capacity as needed. Not everyone can afford to do so, and smaller not-for-profit hosting organisations in particular are struggling with this challenge.
And less visible, medium term impacts
The less visible, medium-term consequence is that critical usage data becomes poisoned. Like contaminated well water , good data that our community relies on to justify ongoing support for publishing, hosting, and licensing of content has been infiltrated with bot-generated usage. LibLynx processes hundreds of millions of usage events each month, and open access content in particular is vulnerable to large spikes in bot-generated usage. We’ve had numerous conversations in recent months with publishers concerned that their usage was increasingly reflecting invasive crawling, rather than human engagement (whether directly or via text and data mining). As is true for all content industries, we don’t have effective tools for understanding the impact of robotic traffic.
LibLynx is planning an R&D project later this year to identify and categorise the different types of robotic activity we encounter (both good and bad) and test strategies for automatically flagging and filtering them out of live access requests and usage event logging. The project will involve publishers from across the industry – both clients and non-clients – and our goal is to document a set of recommendations for publishing platforms that we can share with participants. Contact us if you’d like to get involved.
Who’s talking at Charleston?
I’m very excited to share the stage with three industry leaders from across our community who have a lot of expertise and direct experience to share on this topic:
- Niels Stern, Managing Director of the OAPEN Foundation
- Tim McGeary, Associate University Librarian for Digital Strategies and Technology, Duke University Libraries
- Eric Hellman, President of the Free Ebook Foundation
What are we going to discuss?
We plan to introduce attendees to the scale of the problem, drawing on our diverse experiences in dealing with robotic traffic. We’ll discuss how it’s currently impacting access to scholarly content, and our concerns about the future. And we’ll explore possible solutions.
After a brief overview to introduce attendees to the scale of the problem, we’re going to explore three potential doomsday scenarios:
- The poisoned well of usage statistics – what if we can no longer trust the credibility of usage reports?
- The death of live delivery – what if it becomes cost prohibitive to maintain live infrastructure?
- The end of Open Access – what if content is forced back behind walls?
And we’ll explore possible solutions, both as a panel and with the audience.
We’d love you to join us for the discussion!
And if you’d like to read more on this topic, here are some additional posts we recommend:
- Rosalyn Metz, CTO for Emory University Libraries and Museum. Rosalyn writes an excellent newsletter called The Digital Shift that discusses issues around technology, scholarship, and open infrastructure, including a post on this topic in April: “The Bots Are Coming (for Our Metadata)”
- The Confederation of Open Repositories (COAR) published this report in June, based on a survey of members: “Open repositories are being profoundly impacted by AI bots and other crawlers: Report from a COAR Survey”. Here’s an example survey response – “Every day, multiple bots access the repository at all hours 24/7. We estimate performance degradation due to bot activity about once or twice a day, and at least once a week the system crashes entirely requiring an intervention – typically a service restart.”
- This Scholarly Kitchen post in July by Ben Kaube and Steve Smith explores the deeper implications of bot traffic: “When the Front Door Moves: How AI Threatens Scholarly Communities and What Publishers Can Do”